

Modern autonomy and robotics teams often have excellent engineering hygiene: requirements live in Git, code is reviewed rigorously, tests are automated, and static analysis tools are deeply embedded in CI. And yet, when it comes time to build and maintain a safety case, many teams still struggle.
Not because the work isn’t being done — but because the argument tying that work together is fragile.
In this post, we walk through an anonymized example of how a safety‑critical Safe‑Stop / Emergency Braking Controller can be modeled in Saphira to bridge the gap between Git‑native development and audit‑ready safety cases.
The Problem: Strong Engineering, Weak Safety Narratives
In many mature organizations:
- Requirements are well‑captured and versioned
- Code changes are traceable and reviewed
- Tests exist and are automated
But safety certification still relies on:
- Manually curated spreadsheets
- PowerPoint safety arguments
- Point‑in‑time snapshots that quickly go stale
The hardest question is often not “Is this implemented?” but:
“Can you demonstrate — today — why this system is still safe after months of change?”
That question is about evidence and argumentation, not tooling gaps.
Example System: Safe‑Stop / Emergency Braking Controller
To illustrate this, we model a simplified but realistic safety‑related software component: a Safe‑Stop Controller.
The controller’s responsibility is straightforward:
- Monitor system health and heartbeats
- Detect critical faults or loss of control
- Command a controlled stop within a bounded reaction time
The system is representative of many autonomy and robotics platforms and is well‑suited for ISO‑aligned safety analysis.
Structured Intake: Defining the System Context
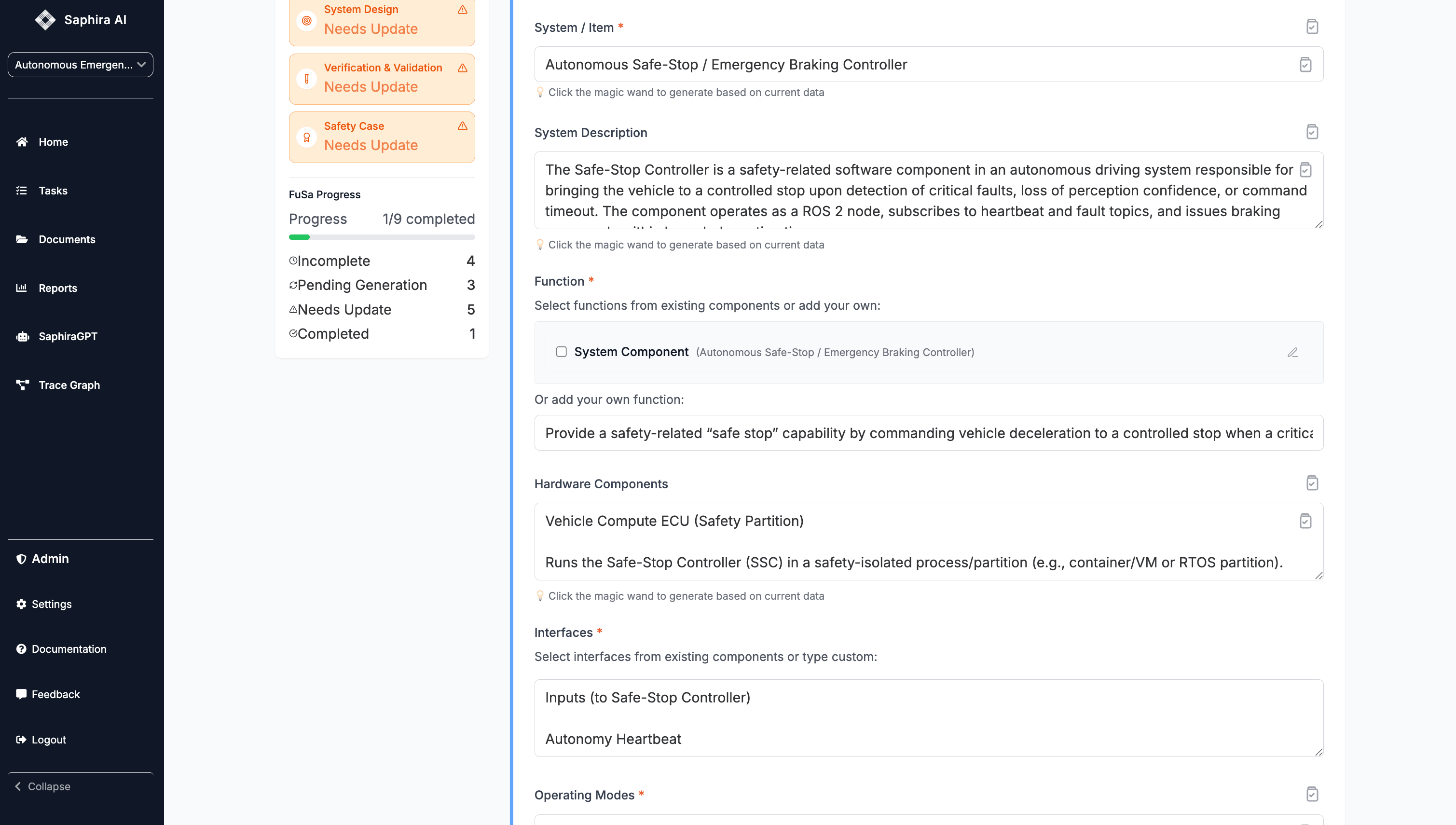
Rather than starting from documents, we begin with structured system context. This is the foundation for generating safety cases that remain connected to real engineering artifacts.
Function
The Safe‑Stop Controller monitors critical signals and transitions the system into a safe state by issuing brake commands when predefined fault or timeout conditions occur.
Hardware Components
- Vehicle compute ECU (safety‑isolated execution context)
- Network interface (CAN / Ethernet)
- Brake‑by‑wire actuator controller
- Optional safety watchdog or supervisor
Interfaces
Inputs include autonomy heartbeats, fault status messages, control authority signals, and timing sources.
Outputs include brake commands, safe‑state status, and internal health heartbeats.
Operating Modes
- Initialization
- Standby
- Active monitoring
- Safe stop requested
- Safe stopping
- Safe stopped
- Faulted / degraded
System Boundary
The Safe‑Stop Controller is responsible for detection, decision‑making, and command issuance — but not for perception, planning, or low‑level brake actuation.
Assumptions & External Dependencies
Key assumptions (e.g., availability of a monotonic clock, reliability of brake actuation) and dependencies (autonomy supervisor, vehicle network, brake ECU) are explicitly captured rather than buried in prose.
This structured intake replaces vague “system descriptions” with machine‑usable context.
From Context to Safety Case
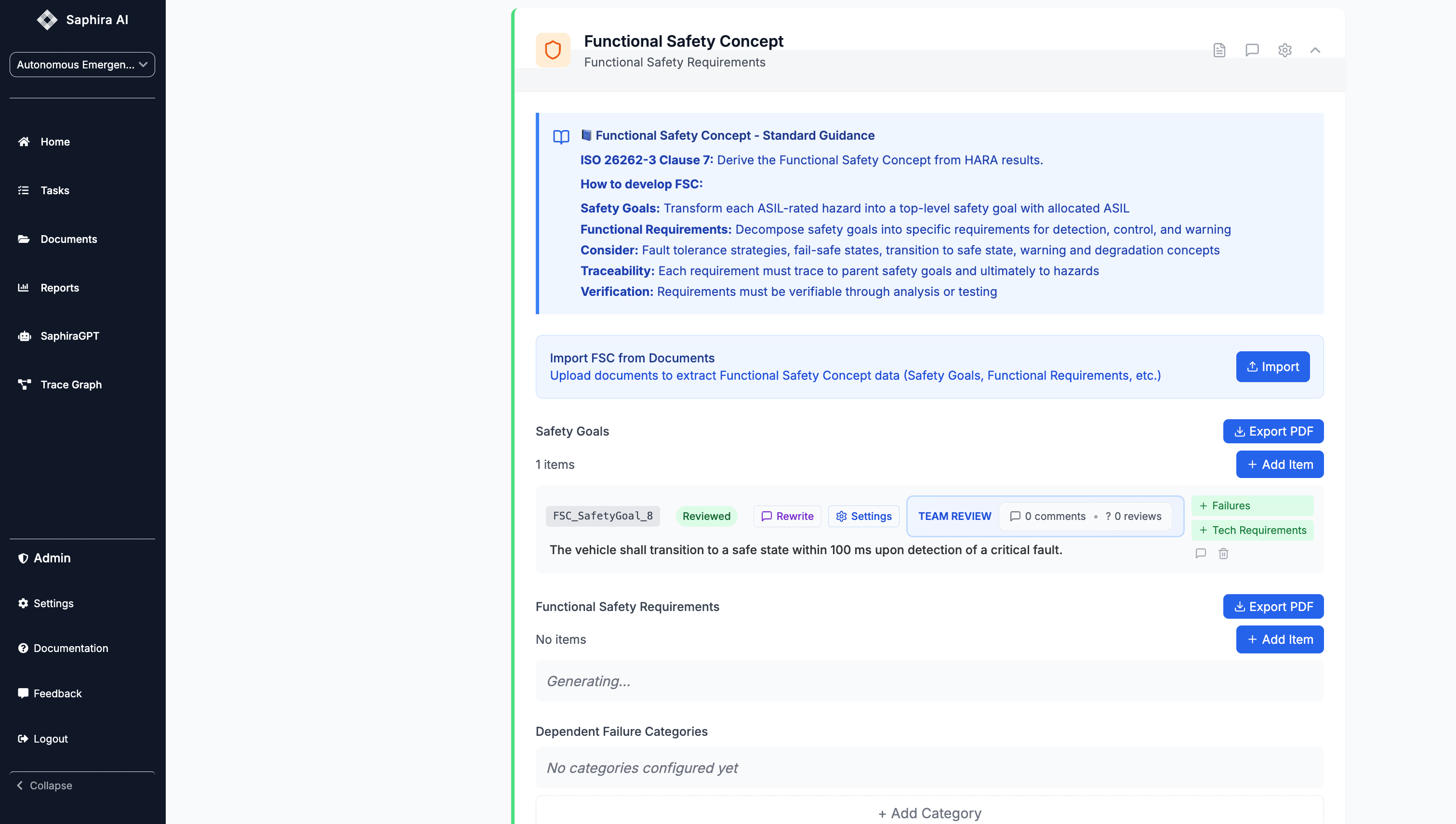
With system context in place, Saphira generates a top‑down safety case.
Example Top‑Level Safety Goal
The system shall transition to a safe state within a bounded time upon detection of a critical fault.
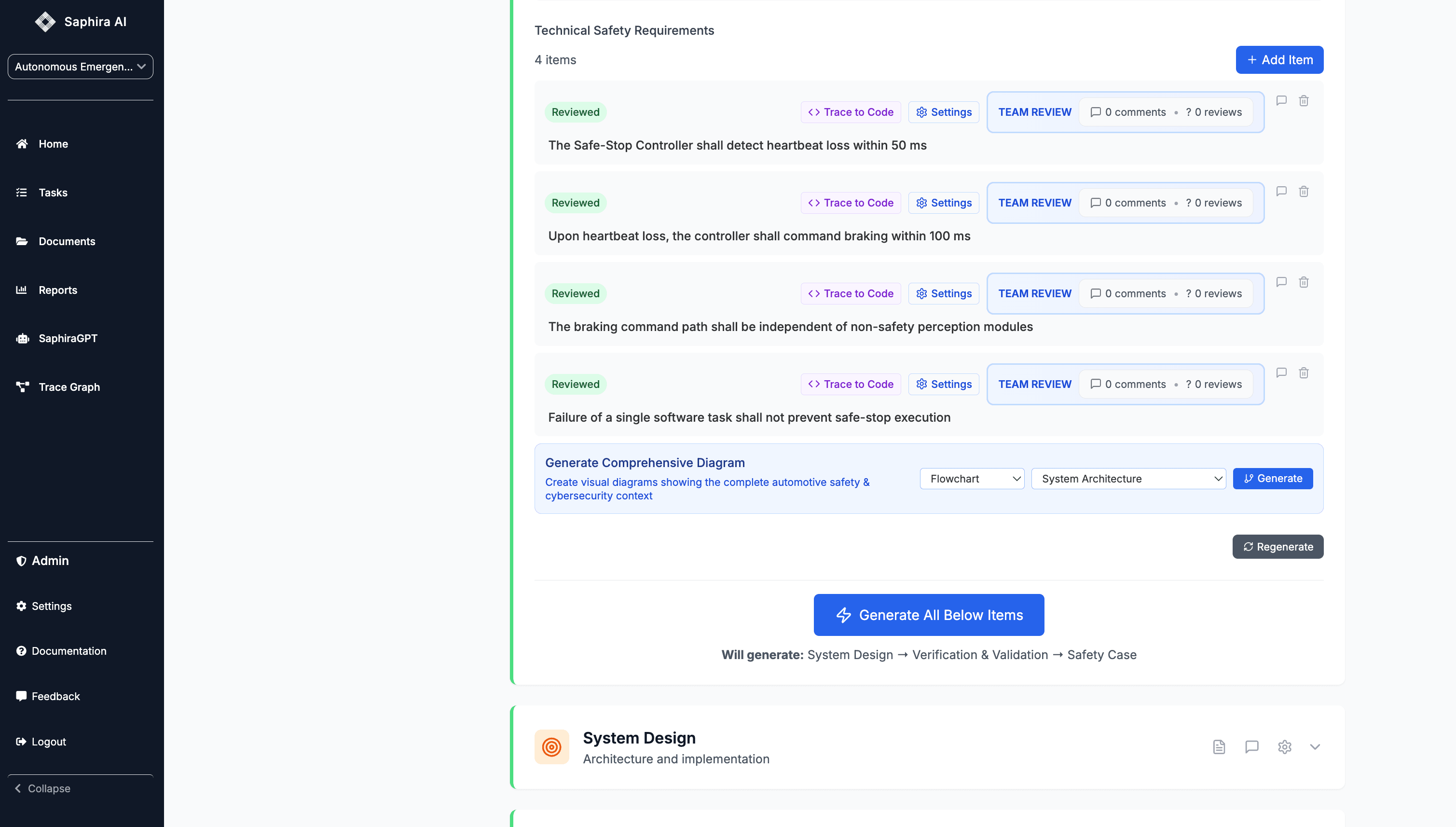
From this goal, Technical Safety Requirements (TSRs) are derived:
- Detection of heartbeat loss within a defined timeout
- Brake command issuance within a maximum reaction time
- Independence from non‑safety software paths
- Tolerance of single‑point software failures
These TSRs are not abstract — they are designed to map cleanly to code and tests.
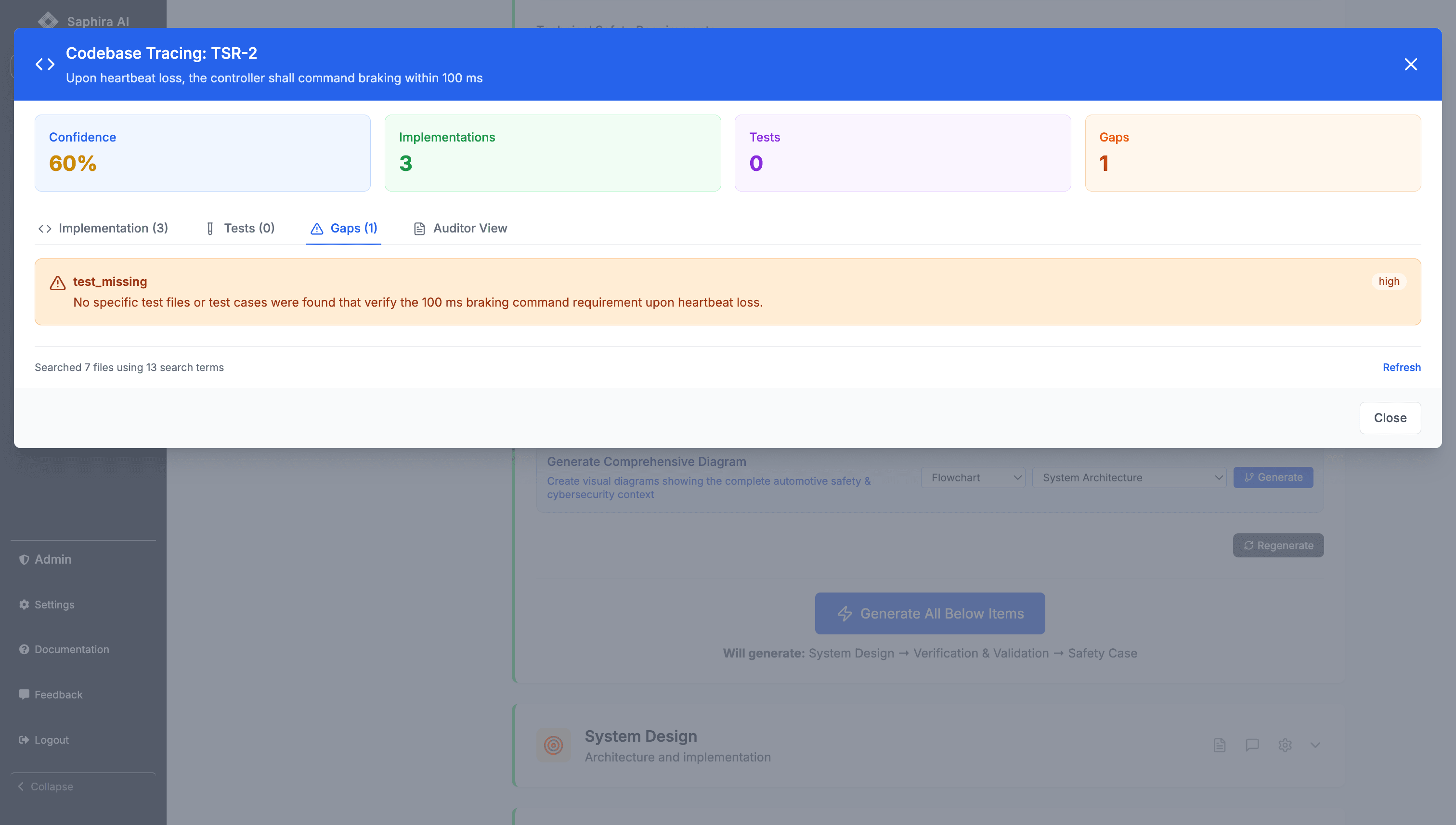
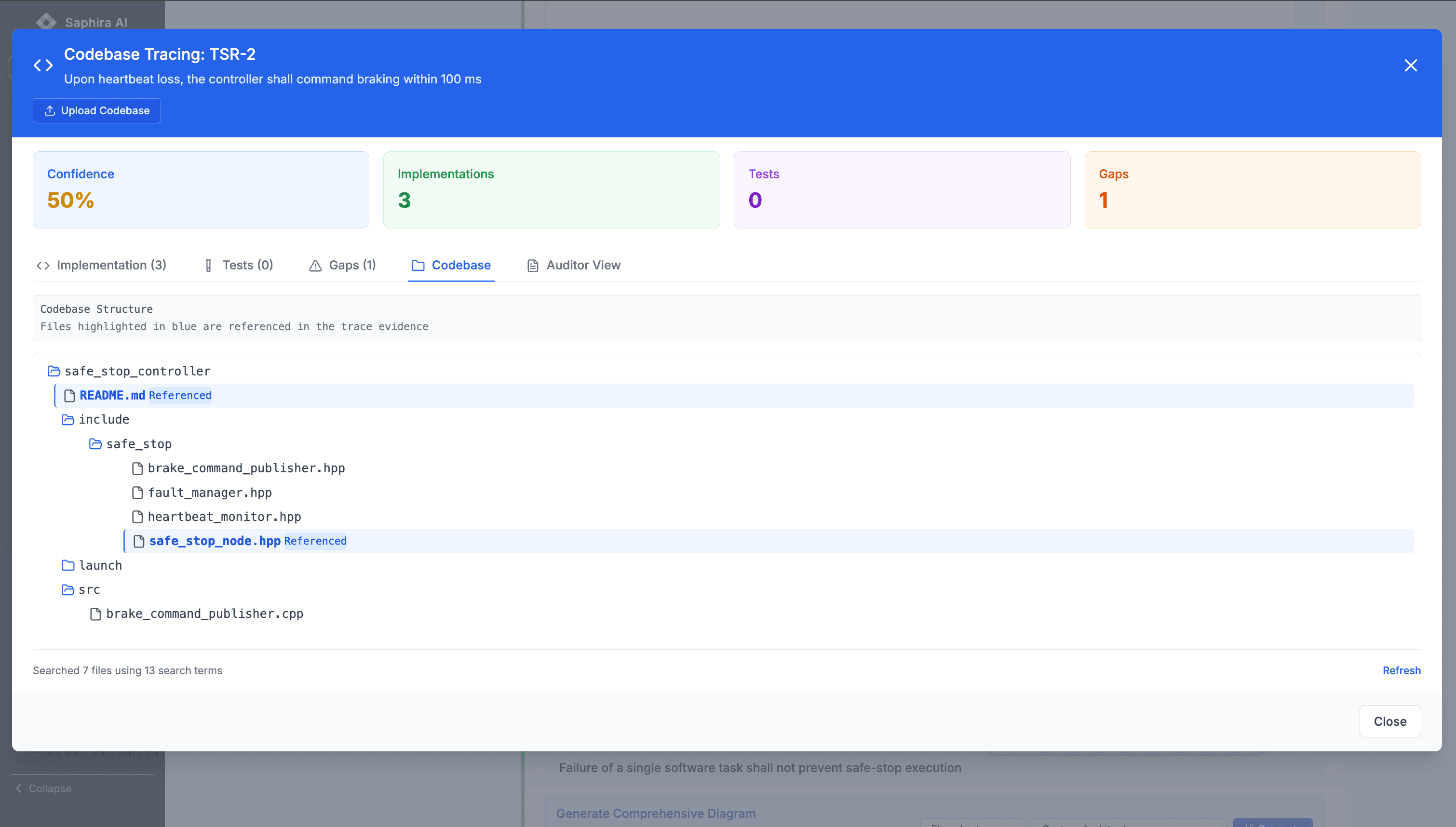
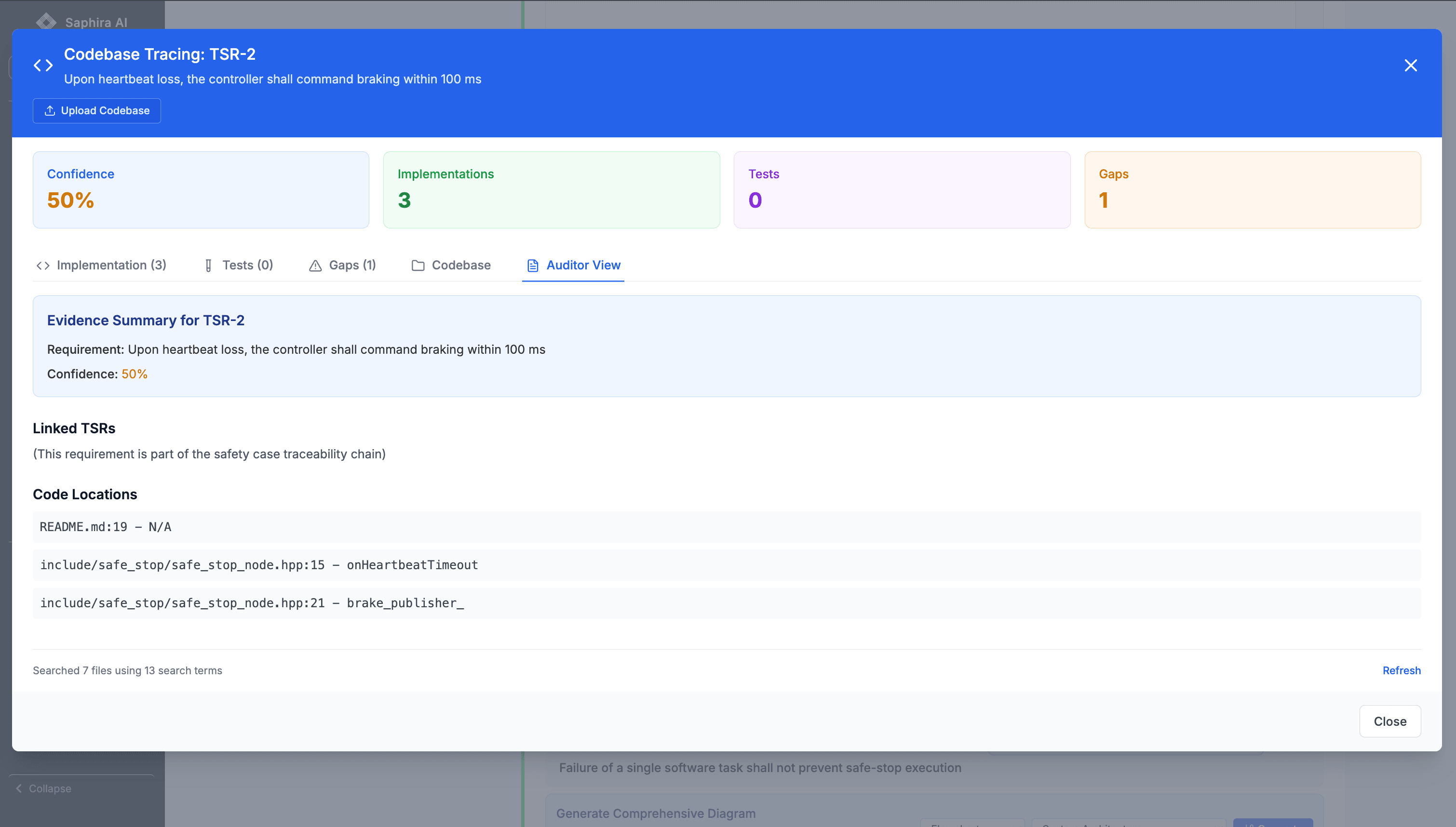
Tracing TSRs into Code and Tests
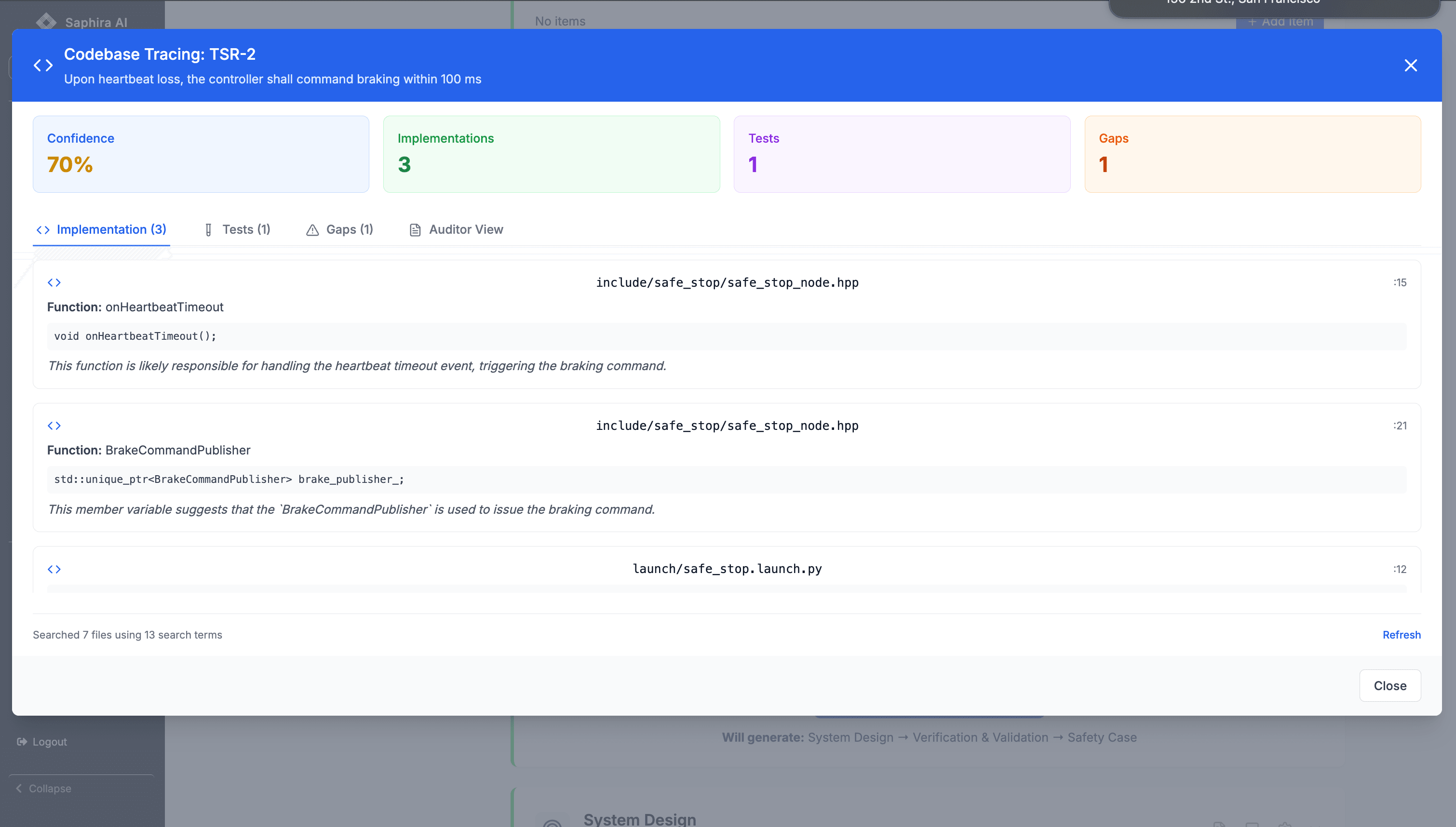
Rather than treating traceability as a static matrix, Saphira treats it as a living graph.
For each TSR, the system can answer:
- Where is this requirement implemented?
- How is it verified?
- What assumptions does it rely on?
- What evidence supports it today?
For example:
- A timeout detection TSR links directly to a heartbeat monitoring function
- A reaction‑time TSR links to both implementation logic and latency‑asserting tests
When evidence is missing or incomplete — such as a test that exists but does not assert timing bounds — the gap is surfaced explicitly.
Change Impact: Where Safety Usually Breaks
Most safety issues do not arise from missing requirements — they arise from change.
By linking safety goals and TSRs directly to code and tests, Saphira can answer a critical question:
What safety assumptions are impacted by this code change?
A modification to timeout logic, message frequency, or execution context can automatically flag:
- Affected TSRs
- Tests that must be re‑run or updated
- Safety arguments that need review
This shifts safety from a reactive certification exercise to a continuous engineering discipline.
Why This Matters
Static analysis tools tell you whether code follows rules.
Saphira helps teams answer a harder question:
What does this code prove — and is that proof still valid?
By compiling safety evidence directly from engineering artifacts, teams can:
- Reduce manual safety documentation
- Maintain coherent safety arguments over time
- Respond faster and more confidently to audits
- Align safety work with real development workflows
Closing Thoughts
High‑performing teams already do the hard work. The missing piece is often not better tools, but better connections between intent, implementation, and evidence.
Treating the safety case as a first‑class, continuously updated artifact — rather than a snapshot — is a powerful shift.
That’s the gap we’re focused on closing.
This example is anonymized and representative of common autonomy and robotics architectures. Specific implementations will vary by platform and standard.

